더 많은 사람들이, 손쉽게, 비용 부담 없이
사용할 수 있는 AI를 향해
전 세계는 지금 AI 붐 속에 있습니다. 더 큰 모델, 더 복잡한 기능이 매일 등장하지만, 모든 문제가 “더 크게”로 풀리지는 않습니다. 빠르면서도, 비용 효율적인 AI가 진짜로 산업을 바꾸는 기술입니다. 스퀴즈비츠는 이 믿음으로, 모델 경량화와 추론 최적화 기술을 통해 AI가 크기와 비용의 한계를 넘어설 수 있도록 하는 데서 출발했습니다.
스퀴즈비츠의 Co-founder들은 AI 경량화·가속화 분야에서 검증된 전문가들입니다. NeurIPS, ICLR, CVPR, ECCV 등 Top-tier 학회에 경량화와 최적화 관련 연구를 지속적으로 발표하며 업계와 학계에서 실력을 인정받아 왔습니다. 매일 새로운 모델이 쏟아지는 시대에, 다양한 하드웨어에서 최적의 성능을 끌어내기 위해서는 알고리즘–소프트웨어–하드웨어 전반에 대한 깊은 이해가 필수입니다. 스퀴즈비츠는 GPU, CPU, NPU 등에서의 AI 연산 구조를 꿰뚫는 전문성을 바탕으로, 누구도 따라올 수 없는 탄탄한 기술력으로 세상에서 가장 빠르고 효율적인 AI를 만들고 있습니다.
Our Mission

전 세계적으로 AI는 빠르게 성장하고 있습니다. 모델은 거대해지고 기술의 범위는 매일 확장되고 있습니다.
끝없이 확장되는 AI의 가능성을 더 빠르게 실현하기 위해서는, 크기와 비용의 제약에서 벗어나야 합니다.
스퀴즈비츠는 경량화와 최적화 기술을 통해 AI의 가능성을 확장한다는 꿈에서 시작되었습니다.
Our Vision

더 많은 사람들이 AI를 실제 업무·일상에서 자연스럽게 활용하고,
합리적인 비용으로 그 효율과 편리함을 직접 느낄 수 있도록 하는 것이 우리의 목표입니다.
스퀴즈비츠는 경량화·최적화 기술을 통해 AI 비즈니스가 더 다양한 현장과 더 많은 사람들에게 활용될 수 있도록 돕는 파트너가 되겠습니다.
Story

2025년 연말 타운홀 - 한 해의 마침표와 새로운 시작
스퀴즈비츠는 전사 팀원이 모여 정기 타운홀 미팅을 진행합니다. 바빴던 2025년을 마무리하며, 연말 타운홀 내용을 공유합니다.
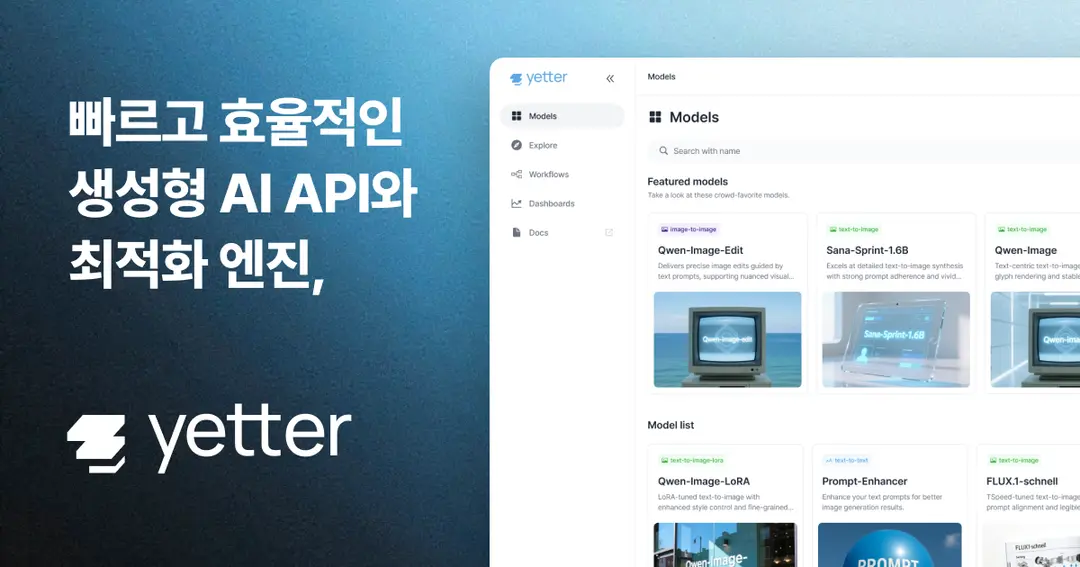
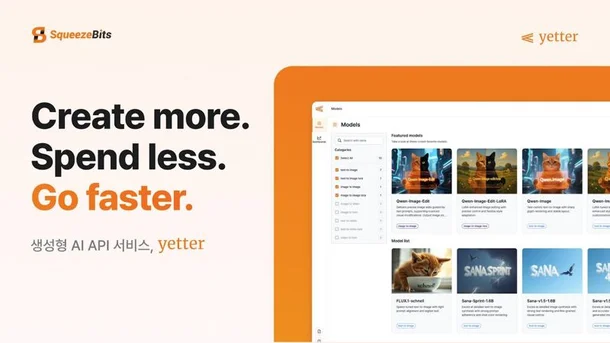
Yetter.ai: 빠르고 효율적인 생성형 AI API와 최적화 엔진으로 완성
스퀴즈비츠의 독점적인 최적화 기술을 내재화한 생성형 AI API 서빙 플랫폼인 예터 (Yetter)를 소개합니다. Yetter AI API와 Yetter Inference Engine에 대해 자세히 알아보세요.

Yetter 브랜딩 구축기 (1) − 브랜드 아이덴티티
생성형 AI API 서비스 Yetter의 브랜딩 구축기. 내부 설문부터 컬러 시스템, 로고 제작까지 브랜드 아이덴티티를 만든 과정을 공유합니다.

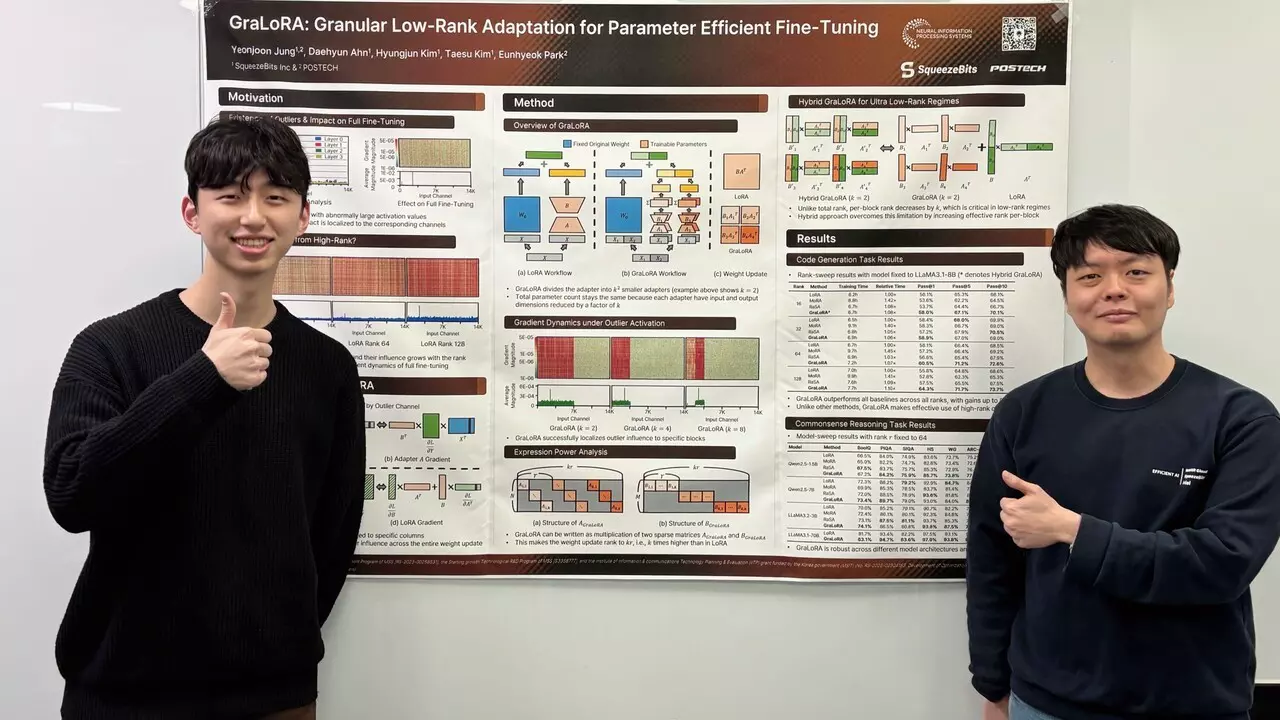
Reliable & Scalable Synthetic Data for Physical AI (Part 2): Making Cosmos 3.1 x Faster for Production
Explore why Physical AI deployment needs synthetic data at scale with Squeezebits' research and discover how to overcome inference bottlenecks to accelerate Roboost Agent.

Reliable & Scalable Synthetic Data for Physical AI (Part 1): Taming NVIDIA Cosmos with RoBoost Agent
Scaling Physical AI requires reliable synthetic data. Learn how RoBoost Agent integrates NVIDIA Cosmos to transform world models into trustworthy data engines for robotics and autonomous driving.

Introducing rebellions ATOM™-MAX
Introducing ATOM™-Max, rebellions’ next-generation NPU designed for high-performance AI inference. Learn how its runtime, profiling tools, and PyTorch-native integrations enable developers to run and serve models efficiently without sacrificing usability.